Product Land (Part 2)
Tools for exploring the margins.

In the part 1 I set out the proposition that the way we think about building digital products is too linear and, as a result, our thinking about what is possible is constrained, with some sectors, I used the example of the ‘job-search’ sector, stuck shuffling around a local minima.
Instead, I suggested we should take a lead from evolutionary biology and start thinking about a hypervolume of potential products - after all, you can’t build what you can’t think of in the first place.
The purpose of this post is to try and start listing some approaches to moving away from the linear design-test-develop-iterate approach. I’ve managed to come up with 6, but the list feels very incomplete, so maybe I’ll add to it if it generates any discussion.
## 1) Writing a list of axes
Making time to think hard of some radically different potential products, and the space they might occupy, can get us a long way.
What might some of the axes for finding work be?
- active vs passive (do you actively engage, or do things come to you)
- money vs other factors
- know what I want vs need suggestions
- specific geographical area vs general area
- understanding the past, right now or some time in the future
- centralised vs distributed
- complete vs partial (knows about every job in the country, or just a subset)
- specialist vs generalist
- low fidelity data vs high fidelity
- general audience vs specific audience
- solitary vs social Most current job-search services can be characterised as active, partial, generalist, solitary, relatively centralised and aimed at generalist audiences.
Here are some alternatives, from different points along those axes:
-
An agreed or enforced open standard for publishing jobs, such as schema.org/JobPosting that makes it easier for other people to build services - distributed, complete, high fidelity data
-
A flashcard tool for quickly sorting all the current jobs within 60 minutes travel time into a yes/no pile - semi-passive, generalist, need suggestions
-
A profiler, Netflix style, that asks you a bunch of questions, then uses a recommendation engine to suggest open positions and resources that have been successful for people like you (e.g. maybe people with a history of cleaning jobs in a certain postcode should try security jobs on a certain job board) - need suggestions, semi-social.
-
A tool for helping someone understand the totality of the local job market - enter a postcode and answer a couple of questions to generate a report showing active jobs by travel to work time, apprenticeships most likely to lead to a full-time job in the area, the most active job boards in a particular area (it varies a lot), a breakdown of types of opening local etc. - need suggestions, solitary, high fidelity data
-
A journal for collecting links to jobs applied for and analytics about applications and interviews over time, maybe for sharing with other people -semi-social, understanding the past, distributed.
-
An online job group where members suggest work for each other - social, need suggestions
Those are just some random guesses but the important thing is that there are a range of guesses - using a set of axes like this forces you to stretch your guesses.
## 2) Asking questions

Libby Miller and Richard Sewell created Catwigs to help product teams think about the direction of a project. Catwigs is a pack of 22 cards that asks questions with extreme answers - e.g. “Does it solve a problem” is answered on a scale between “Antibiotics” through “Garage door remote” to “Cat wig”.
The aim of Catwigs is to engage in a discussion about the direction of a project in a new way, but I wonder if the Catwigs cards, or something like them, might have a secondary function - of better understanding some alternatives up front?
Is it enjoyable?, What is the size of the market and Does it rely on network effect all feel like useful questions to ask of our hypothetical job-search product space - you could build both a product that is enjoyable, has a small number of users you want to target, does not need a network effect and a product that has lots of users, relies on network and is dull-but-useful.
[You can buy a set of Catwigs and Libby has written up the background to the project.]
## 3) Building 2 of everything
A couple of months ago, Ars Technica published an article entitled Google’s product strategy: Make two of everything.
In it they suggested that, rather than seeing Google’s constant retiring of products as failures, we should view them as research at scale - using two or more products to explore the potential product-space, the limits of newly arrived technology and platform strategy with real users. Think Android/ChromeOS, Glass/Android Wear, Wave/Google plus.
This makes sense to me - sometimes the only way to know how people will react to something over time, and how a team’s thinking will evolve, is to put it in from of real users for real over a number of months.
As it becomes simpler to build almost any digital service - and design becomes more about intelligent assembly of technology components (due to mature frameworks and code libraries, services like Twillio and Mailpile, easy hosting on Heroku, quick prototyping with Arduino, app style APIs for web pages, css and javascript frameworks, etc.) this approach stops being the reserve of Google and is within reach of small teams. Things that were previously too niche too or expensive to build are suddenly practical.
So, why not build a standard job search and a flashcard tool and a job-market profiler, and …, run them for 6 months to understand more broadly what works and what doesn’t, then wrap that learning into the next generation of products? This is not to say that lab testing does not also help a team understand a problem space, but some things need testing in the wild and doing that testing is getting cheaper and easier.
## 4) Hackdays
The great lie about hackdays is that they lead to finished products, and that it is a failure of the organisers when ideas are allowed to wither.
The real benefit in hackdays is swarming lots of people around a theme and coming up with lots of potential products.
They also allow anyone, not just someone who self-identifies as a designer to create something user -facing. This is especially important with emerging specialist domains - the example of a Netflix style job profiler is more likely to come from someone with good knowledge about the current state of recommendation engine technology.
[Incidently, Ben Field’s talk ‘Customers Who Bought Music Also Bought Beer’ on recommendation engines is brilliant].
## 5) Understand what technology has done to the product-space
Ongoing technical/digital change is seemingly a constant at the begining of the 21st century.
The result is people’s expectations and what is technically possible are a moving target and the potential product space may be different from when you built something 6 months or 3 years ago. The potentual product-space is forever shifting and changing shape.
This is pretty well understood in biology - that the fitness (likelihood of reproduction) of a given set of characteristics can change with time:
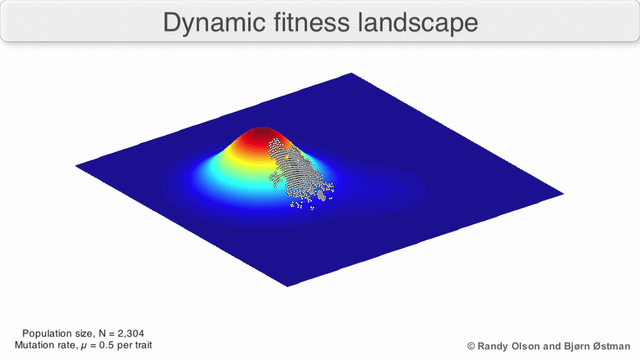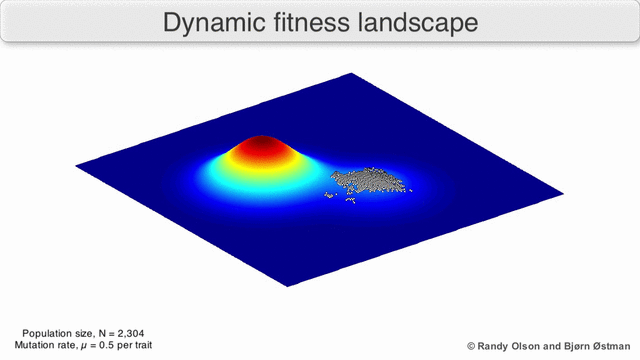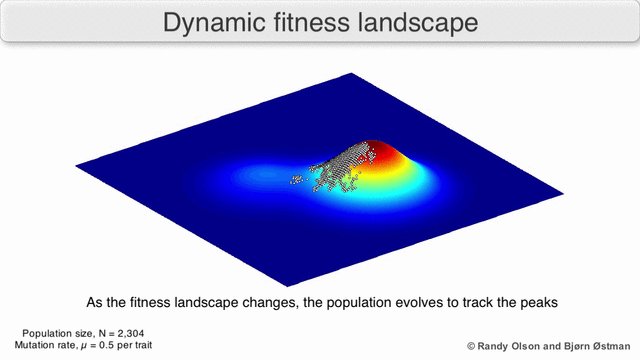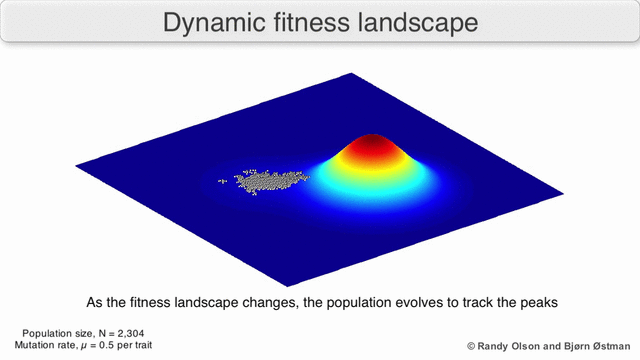
The technology landscape which ‘finding a job’ sits in has certainly changed. The emerging schema.org/JobPosting standard I’ve mentioned; there are mature, open-source, libraries for the sort of things you need to do clever automated matching like tf–idf and collaborative filtering; there’s also growing mobile usage, push alerts, easy to implement geo location and open travel time data. All of those change what it is possible to build today.
I don’t think there is a missing capital-m-methodology here, it’s more about making sure there is time upfront to ask: ‘what has changed’ since someone last tried to solve something in this product space? What is possible that was not possible a couple of years ago?
Charlie Stross’ Programming Perl in 2034, Tom Coates’ Is the pace of change really such a shock? and Eric Schmidt’s How Google Works explain change, technology and time better than I ever can.
## 6) Automated design?
[I hesitated about putting this section in, but left it in because there is something interesting happening here, even if it’s not yet clear what it is]
The pages that I see on Amazon and Facebook are different from the ones you see, and that is as much down to a computer and a big stack of data about me as it is the intervention of a human designer. Automated/semi-automated design is already here. On-going, automatic, data driven experiments are forever probing the edges of product space.
Where it goes next is interesting. Do we end up with tools for generating a range of designs with a human just guiding the process, much as Biomorphs are selected for a given trait?
I’m totally out of my depth here, but I think there is something interesting, and it doesn’t feel like too much of a crazy statement to say how things get designed and the skills required to do it is begining to change.
The future of design: stay one step ahead of the algorithm by Dan Saffer and The automation of design by Jon Bruner are both worth a read on this subject.
## What else?
As I said above, this list feels very incomplete. Ultimately though, I think it comes down to:
- do anything that expands your understanding of the potential space
- design is much more about technology than it is popular to admit
- don’t just assume you are building one thing There’s one aspect of product space, I’ve not really gone into yet, which is the subject of power in product design. That will be part 3.